在实际考虑堆利用方法时,chunk size的计算是个需要小心的地方,因为这里包括了 prev_size的复用,以及根据不同系统考虑的对齐情况,还有 chunk 的size位表示的是包括chunk header在内的size,而实际可用的size与此不同,它是减去chunk header后的大小。
我们还可以根据不同的条件去构造不同的chunk复用,像是只利用一个字节溢出(off-by-one)来使chunk size减小,以此来构造的poison_null_byte 漏洞等等。了解chunk复用的原理,就是去改变 size 位来使系统对错误的长度进行 malloc、free,这就是我们的目的。
近期做了一道题,对我的感触颇深,所以将其中用到的思想在此处进行展示:
- 堆块对堆的初始位置是没有任何限制的,也即堆块不一定要满足对其的条件。堆可以以0x6030f5开始
- 堆块大小的计算。#define chunksize(p) ((p)->size & ~(SIZE_BITS)) 其中~(SIZE_BITS)=0xfffffff8
- fastbin大小计算。(((sz)>>(SIZE_SZ==8?4:3))-2) 在针对fastbin attack或者double free时,保证fastbin大致相同具有十分重要的意义。例如0x7f的fastbin与0x70大小的fastbin在同一条链上。因此很多时候就可以构造0x7f大小的fastbin,代替很难找到的0x71\0x70大小的fastbin
- fastbin取值范围32位[16-80],64位[32-160] 貌似总共有9个,实际上只能用前8个
0×01 Use After Free
要学习堆中的漏洞,最基础不过的就是这个 UAF 了,UAF 漏洞原理很简单,就是在 free 掉 chunk 后,指向该 chunk 的指针还能正常使用
|
|
编译运行一下
|
|
我们可以看到 p 指向的函数地址被我们用1234给替换掉了,这就意味着我们能够利用这样一个漏洞控制 rip 寄存器,执行指令。
0×02 unlink
unlink漏洞想必大家都不陌生,在前面我们提到过,系统通过 unlink 宏将 free chunk 从链表中取出,但是我在这里强调一下,并非所有从链表中取出 chunk 的操作都利用到了 unlink 宏,要知道,我们在 malloc 时,也多次将 chunk 从 bin 中取出,我想结合部分源码(只截取了取出部分的代码)来强调一下 unlink 的使用状况。
在 malloc 操作中,我们多次进行了 bin 之间的转移,具体如下
victim指的是被取出的地址
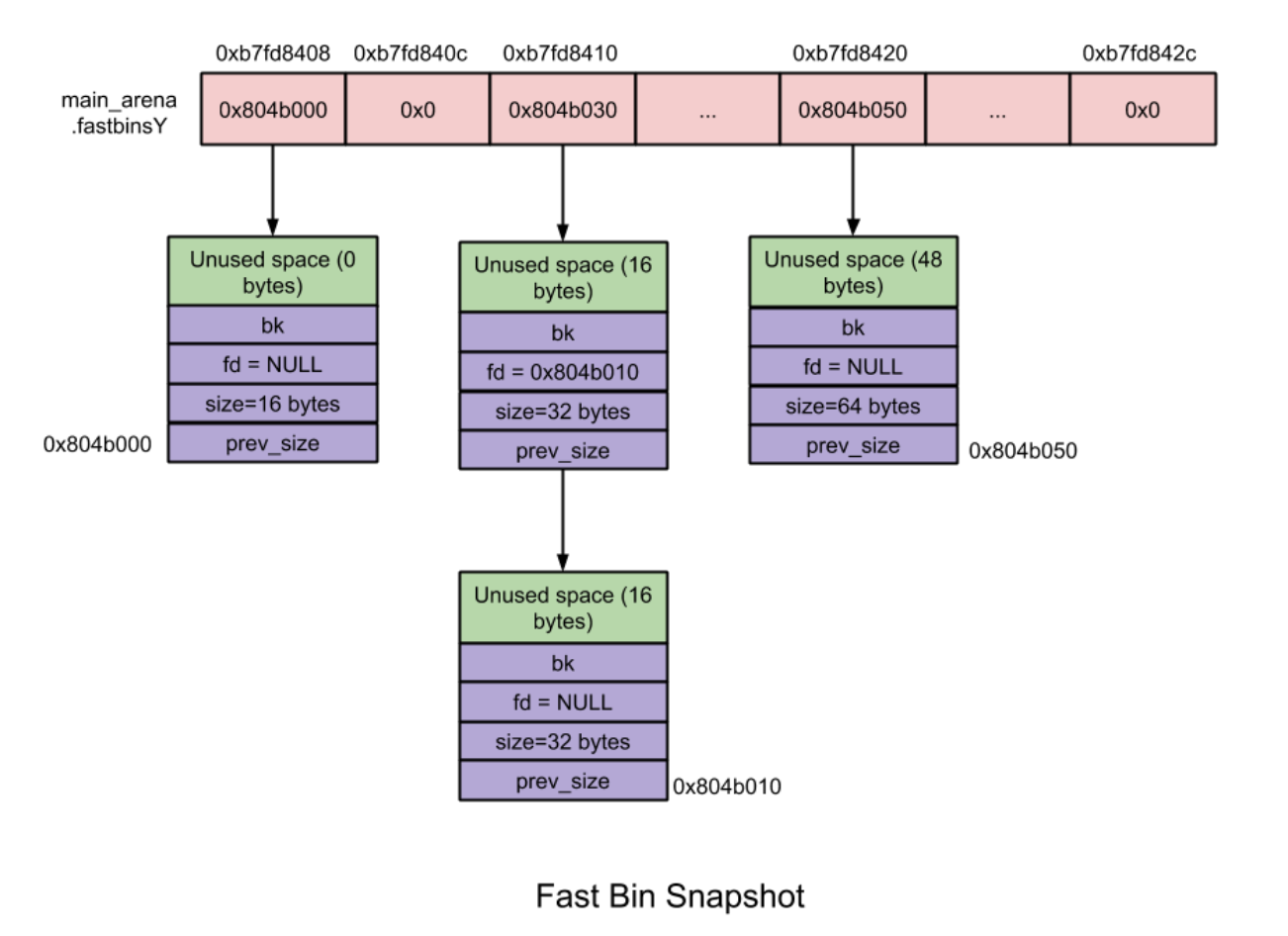
从 fastbin 中取出 chunk (fastbin后进先出)
123mfastbinptr* fb = &fastbin (av, idx);victim = *fb;*fb = victim->fd;从 unsortedbin 中取出 chunk
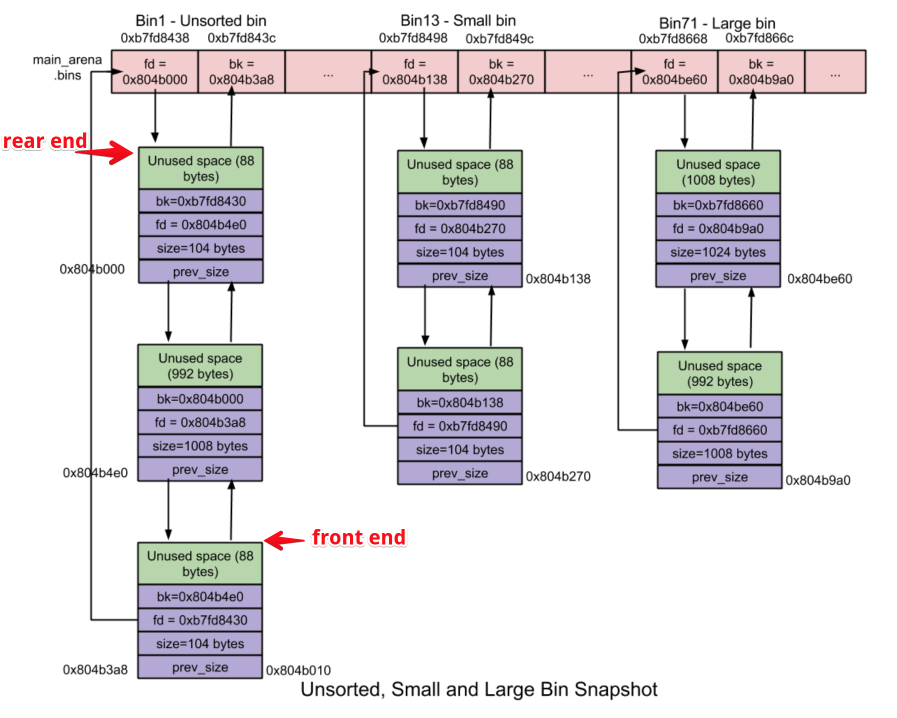
1234victim = unsorted_chunks(av)->bkbck = victim->bk;unsorted_chunks(av)->bk = bck;bck->fd = unsorted_chunks(av);从 unsortedbin 向 smallbin 转移 chunk
1234if (in_smallbin_range(size)) {victim_index = smallbin_index(size);bck = bin_at(av, victim_index);fwd = bck->fd;从 unsortedbin 向 largebin 转移 chunk
12345mark_bin(av, victim_index);victim->bk = bck;victim->fd = fwd;fwd->bk = victim;bck->fd = victim;从 smallbin 中取出 chunk
123456idx = smallbin_index(nb);bin = bin_at(av,idx);victim = last(bin);bck = victim->bk;bin->bk = bck;bck->fd = bin;从 largebin 中取出 chunk
1unlink(victim, bck, fwd);合并 fastbin 中 chunk 并加入到 unsortedbin 中(单向链表,bk指针需要获取)
(这种情况比较特殊,如果实在找不到内存分配的话,可能会调用malloc_consolidate这个函数,它就会合并fastbin到unsortedbin中)
1234567prevsize = p->prev_size;size += prevsize;p = chunk_at_offset(p, -((long) prevsize));unlink(p, bck, fwd);......size += nextsize;unlink(nextchunk, bck, fwd);我们发现不仅仅在 free 时进行向前向后合并时使用 unlink 宏,在 malloc 时也会有零星的 unlink 使用,而且一定要注意,上面的除了6、7外,在进行取出 chunk 操作时,并没有进行 unlink,所以在对这一部分进行漏洞利用时,不需要考虑 unlink 的检查。
现在言归正传,来看看 unlink 漏洞。
|
|
上面所示是 unlink 宏的主要实现,我们现在设想申请两个chunk,并利用第一个chunk溢出到第二个chunk的size位,将第一个chunk的 inuse 位改写为 free状态,这时候我们再free第二个chunk,此时系统通过第二个chunk的size检查第一个chunk,发现他是free状态,那么这时候就会使用unlink将第一块chunk从bin中释放出来并与第二块合并
|
|
这时候其实a并没有在 bin 中,但是如果我们对 a 的前两个元素(即”fd”、”bk”)进行构造,那么就可以造成任意地址写入。
首先我们需要绕过检查,我们进行一个小小的计算(下面的栗子是64位系统)
|
|
发现我们只需要在 b 的”fd”指针处放入 b-0×18,在”bk”指针处放入 b-0×10,即可绕过检查
执行完 unlink宏后,我们的b变成了这样
|
|
也就是说 现在 b 处存放着 b-0×18 的地址,这时候我们再向 b 写入数据也就是向 b-0×18 处写入数据了
|
|
这时候我们通过两次写入来造成任意地址写入(假设我们能够写[b]的值,而且没有长度限制)
第一次写入0×18个字节,最后几位放入要写入的地址(此时覆盖了b)
|
|
我们再次写入时,就是修改该地址处的数据了,比如修改got表什么的(此时是对上一次写入的地址进行任意修改)
0×03 unsortedbin attack
对 unsortedbin 的攻击主要利用从 unsortedbin 中取出 chunk 的操作来进行向任意位置写入一个不可控的指针,注意这里,从unsortedbin链表中取出chunk并不是使用unlink宏,所以不需要绕过 unlink 检查。首先我们需要创建两个 chunk 来避免 free 第一个 chunk 时将该 chunk 并入 top chunk(因为不连续,所以不会被合并),并且第一个 chunk 要足够大,确保其能进入到 unsortedbin中
|
|
然后将 p free掉,此时 p 进入到 unsortedbin中,然后改写其的 bk 指针,并malloc
|
|
我们看一下从 unsortedbin 中取出 chunk 的操作
|
|
这个漏洞自由度较小,不过可以用来修改一些阈值,例如更改libc中的max_fast,从而使得任意分配都使用fastbin来实现,为其他漏洞提供方便。
0×04 fastbin attack
还记不记得我们在第一篇中那个介绍 fastbin 中 dobule free的例子
|
|
这个运行是没有问题的,但是想象一下,这样做之后,现在的 fastbin 中是什么样子
|
|
其中的指向关系由chunk的 fd 指针标识。此时我们再从 fastbin中 malloc 出一个 chunk
|
|
此时的 fastbin
|
|
现在我们得到了一个chunk,并且这个 chunk 同时在 fastbin中也存在,那么此时如果我们修改 c 的 fd 指针位置为任意地址,那么 fastbin 中 a 的指向也会发生改变
|
|
我们之后连续 malloc 两次
|
|
现在的 fastbin
|
|
那我们再次 malloc 时,就可以在任意地址创建一个 chunk 了,但是要注意的是,我们在之前提到过,从 fastbin 中取出 chunk 的时候会对 chunk 的size 做检查,也就是这个任意位置的 chunk 的 size 位必须构造。我们可以在栈中构造
|
|
这个变量作为size位,我们可以将任意地址填充为 &stack – 8,然后 malloc 之后会返回这个地址的 chunk,在栈中变量无法溢出时,我们可以向 chunk 里面写入数据来造成栈溢出。
|
|
fastbin attack 中令人兴奋的一点是,它不需要对 chunk 进行溢出就可以进行攻击,这在一些对输入长度检查严格的地方可以得到奇妙的应用。
0×05 overlapping chunk 1
幸运的是,并不是所有的程序都会对输入长度有严格的约束,当我们能够溢出到下一个 chunk 时,我们可以修改它的 size 位来造成 chunk 的覆盖。
首先,我们创建三个chunk,考虑 prev_size 的复用和 0x10字节对齐,我们将 malloc(0x100-8), 系统会给我们(0x100-8)+0x10-0×8,即0x100(0x10对齐)的空间,实际可用的空间正好是0x100-8,并没有多分配,而要是malloc(0x100)的话,你会看到实际可用的空间是0x108(这个不是必须的,只是向大家强调一下 chunk 大小的计算)
|
|
然后 free 掉 b,b就会放到 unsortedbin 中 ,这个bin只有一个链表,并不对size进行区分,所以我们可以放入0x100的chunk,修改为size为0x180后就可以拿出0x180的chunk
|
|
然后我们利用a溢出到b的size位
|
|
现在我们malloc一个0×180的 chunk,系统就会将从b开始的0×180大小的空间返还,这其中包括c
|
|
ok,现在我们就可以更改利用d更改c中的内容,如果c中包含某个函数指针,我们也可以去改变它.
0×06 overlapping chunk 2
我们在前面先释放再修改size来获得了一个覆盖掉后面chunk 的 chunk,那么如果我们先修改size为一个大值,然后free会怎样呢?
首先我们创建4个chunk
|
|
我们通过a溢出到b的size
|
|
我们这里讲b的size扩大到了c,由于free时需要检查下一个chunk的size,所以我们预留了d,并且防止free后直接与top chunk合并,之后我们free掉b,然后再次malloc就又包括了c
|
|
然后就可以可以像0×02一样去利用。
0×07 House of spirit
假设我们可以在栈上伪造出一个chunk结构,那么我们可不可以利用free来释放,再次malloc得到这个chunk呢?House of spirit就是这个思路,当我们在栈上伪造出 chunk,并绕过检查的话,那么就可以实现
首先我们需要伪造chunk,但是要记住,在free执行的时候,会有一步检查,检查下一个chunk的size是否大于2*sizeof(size_t),并且小于所有分配的空间,所以我们需要构造两个size位。
我们假设栈上有一个数组可以填充数据
|
|
我们开始构造要free的chunk的size
|
|
然后为了绕过检查,需要在这个chunk后面紧跟一个chunk,设置其size位
|
|
然后我们把 fake_chunks[2] 的地址作为参数调用free。堆块中,size的下一位为malloc返回的地址
|
|
此时再进行malloc就可以得到该处的chunk
|
|
0×08 House of lore
在前面的 House of spirit 中,我们尝试在栈上伪造了一个 chunk,那么接下来在 House of lore 中,我们将尝试伪造一条 smallbin链表,注意看,这里会用到我们在第一篇中讲过的 malloc分配流程的内容。
首先我们需要创建两个chunk,第一个用于进入smallbin中,第二个用来防止free后被top chunk合并
|
|
接下来我们要将这个 victim 送入 smallbin 中。
|
|
我们先将其free掉,现在它位于unsortedbin中
|
|
接下来,我们再次申请一个size位于largebin中,并且在unsortedbin中没有与其匹配的chunk,所以我们需要一个大值。
设想一下,接下来会发生什么?
系统依次找完 fastbin、smallbin、unsortedbin后发现找不到这个size的chunk,接下来会把unsortedbin中的chunk加入到smallbin或者largebin中,这时,我们的victim就成功进入smallbin中了。
现在我们假设可以控制 victim的fd、bk指针,我们就可以在栈上伪造出一个smallbin的链表
|
|
那么我们再次malloc时,就可以从smallbin的链表末尾取chunk了。这里应该是stack_buffer_2
|
|
而当我们在栈上创造出 chunk 后,就可以向chunk中写入来覆盖返回地址控制eip,甚至绕过 canary检查。
0×09 House of force
在 House of force 中,我们这样设想,如果我们能够将top chunk的size覆盖为一个巨大的值,是否就可以实现malloc从堆直接到.bss段、到栈?
我们首先创建一个 chunk,紧跟着这个chunk的就是top chunk
|
|
我们设法溢出到top chunk
|
|
那么现在top chunk 的size 就是 0xffffffffffffffff,现在我们可以计算一下从top chunk的起始地址到我们要覆盖的地址之间的距离,然后malloc一个巨大的chunk填充这一段距离,然后再次malloc一个小chunk,向小chunk中写入数据就可以改变这里的值。
|
|